データドリブン経営の前提として考えるMVV:ミッション・ビジョン・バリューと戦略・戦術・戦法

前回記事、「Oracleデータベースで、波ダッシュの文字化けはなぜ起きるのか?」では、Oracleデータベースに格納されたテキストの「波ダッシュ」の文字化けについて書きました。
そのとき、Unicodeコンソーシアムで登録されている波ダッシュの字形が、正しくない形で登録されたことを説明しました。
| 16新コード | 字形 | |
| [Shift_JIS]の波ダッシュ | 0x8160 |  |
| [Unicode]の波ダッシュ | U+301C |  |
| [Unicode]の全角チルダー | U+FF5E | |
[Shift_JIS]の[0x8160]は、[Unicode]の[U+301C]と同じ名称で、[Unicode]の[U+FF5E]と似た文字の形をしている、ということでした。
お手持ちの環境で試されたかたもいらっしゃると思いますが、Vista以降のWindowsの環境を使った方は、「あれっ?」と思われたのではないでしょうか?
メイリオフォントで確認してみると、
| 16新コード | 字形 | |
| [Shift_JIS]の波ダッシュ | 0x8160 | |
| メイリオの波ダッシュ | U+301C |  |
| メイリオの全角チルダー | U+FF5E | |
あれ?[Shift_JIS]と同じ形になっている?
[Unicode]の仕様が変わった?
いえいえ、[Unicode]の仕様は変わっていません。
Unicodeコンソーシアムの定義は文字コードごとに分かれており、[U+301C]と[U+FF5E]は以下に記載されています。
http://www.unicode.org/charts/PDF/U3000.pdf
http://www.unicode.org/charts/PDF/UFF00.pdf
この資料は、Unicode 7.0のもので、2014年に作成されたものです。
なので、2014年現在も
| 16新コード | 字形 | |
| [Unicode]の波ダッシュ | U+301C | |
| [Unicode]の全角チルダー | U+FF5E | |
が、Unicodeコンソーシアム的には正しい字形です。
Windows Vista以降のOSになると、かなりのフォントでは[Unicode]の「WAVE DASH」が左から「上がって下がる」字体([Shift_JIS]の「WAVE DASH」の字形と同じ)に変更されています。
しかし、[Shift_JIS]の[0x8160]が変換される[Unicode]の16進コードは相変わらず[U+FF5E]ですし、字体が変更されたことにより、[Unicode]の[U+FF5E]と[U+301C]は、見た目が一致する文字なのに16進コードが異なる文字、ということになってしまっています。
Windows XPとWindows Vistaそれぞれ、OSに付属している文字コード表を使って[U+301C]の文字を見てみます。
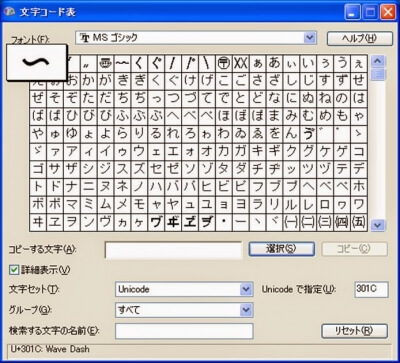
Windows XPの文字コード表で「MS ゴシック」フォントを使って、[Unicode]の「U+301C」を選択した画面です。
字形がUnicodeコンソーシアムの 定義にある「WAVE DASH」と同じになっていることがわかります。
また、この画面からはわかりませんが、[Shift_JIS]の[0x8160]は、 [Unicode]の[U+FF5E]に変換されます。

Windows 7の文字コード表で、同じく「MS ゴシック」フォントを使って、[Unicode]の「U+301C」を選択した画面です。
Windows XPと同じフォントセットなのに字形が変わり、[Shift_JIS]の「WAVE DASH」と同じになっていることがわかります。
字形は変わりましたが、[Shift_JIS]の[0x8160]は、相変わらず[Unicode]の[U+FF5E]に変換されます。
この字体の変更がいつ行われたのかは、フォントによって異なります。
例えば、MS 明朝およびMS ゴシックでは、フォントのJIS2004対応(Windows Vista)およびその旧字体(JIS90)互換用フォントのリリースと同時に変更されていますし、メイリオでは当初から[Shift_JIS]の「WAVE DASH」と同じ字形で提供されています。
参考として、筆者が使っているWindows 7環境に導入されているフォントのうち、[U+301C]を持つフォントで[Unicode]の「WAVE DASH」と「FULLWIDTH TILDE」を並べて出力してみました。

それぞれ、[U+301C][U+FF5E]の順で並べています。
MS 明朝/MS P明朝 のように2つの字形が異なるフォントもありますが、ほとんどのフォントは全く同じ字形です。
(notepadなどを使用して表示したとき、[U+301C]の字形が汚く見えるのは、そのフォントが縮小フォントを持っていないためです。だいたい18ptくらいのサイズにすると、キレイに見えるようになるはずです)
[U+301C]を持たないフォントは代替フォントで表示され、 こんな感じに見えます(左が代替フォント)。

ここまでWindowsを基準に書いてきましたが、同様に、この2文字をiOS、Android、Linuxの、Microsoft以外の環境で表示してみると
Apple iOS 8.1

Android 4.4

Linux (Fedora 20)

いずれも、同じ字形に見えます。
「字体が正しくなったし、これで問題解決」かというと、実はそんなことはなく。正しい字体が表示されることによって、余計やっかいなことになるかも知れません。
前回説明したとおり「波ダッシュ」は、環境によってどちらの文字を使用するかが異なります。
iOS、Android、Linuxなどの環境では、「波ダッシュ」は16進コードの[U+301C]で入力されます。
Windows環境では、「波ダッシュ」は16進コードの[U+FF5E](全角チルダー)で入力されます。
ということは、これら2つの環境それぞれで入力した
「なが〜い」
と
「なが~い」
の2つの文字列は、見た目は同じでも「波ダッシュ」16進コードが異なるので、テキスト検索では一致しない文字列、ということになるのです(なので、データ側を何とかして同一のコードに揃えるか、検索側で何とかしなければならないのです)。
「見た目が一致する文字なのに16進コードが異なる文字」って、見た目が違う以上にやっかいだと思いませんか?
Oracleデータベースで、波ダッシュの文字化けはなぜ起きるのか?
20年以上の実績に裏打ちされた信頼のデータ連携ツール「Waha! Transformer」で、自社に眠るデータを有効活用。まずは無料のハンズオンセミナーや体験版で効果を実感していただけます。

Rankingランキング
New arrival新着
Keywordキーワード