データドリブン経営の前提として考えるMVV:ミッション・ビジョン・バリューと戦略・戦術・戦法

複数のデータベースや業務アプリケーションから取得したデータを扱うときに、「文字化け」に遭遇することはままあることだと思います。
などなど、さまざまな原因があります。
今回は、Oracleデータベースに格納されたテキストの中にある~波ダッシュ~の文字化けを取り上げ、なぜ文字化けしてしまうのかを説明します。
Oracleデータベースに接続したときに「~波ダッシュ~」が文字化けするという話、よくあります。
例えば、
のように、「波ダッシュ」の文字化けは、データベースとクライアント間の文字コード変換が原因です。
では、なぜこの「~」の文字化けだけよく起きるのでしょうか?
今回の話の主役である「波ダッシュ」という文字は、「朝~昼」のように「から」にあたる意味や、「なが~い」のように「ー」より長い長音記号の意味、「~~~~」のように複数つなげて区切りの意味、などで使われる文字です。
JIS規格(JIS X 0208)では「波ダッシュ(WAVE DASH)」という名前で定義されています。[Shift_JIS]での16進コードは[0x8160]です。
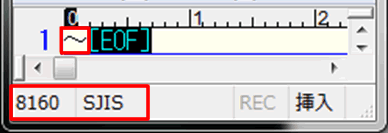
図はWindowsで動くエディタで「~」を入力した例。
ステータスバーに、入力した「~」が16進コードの[0x8160]であることを表す「8160」と、文字コードが[Shift_JIS]であることを表す「SJIS」が表示されています。
[Shift_JIS]の「波ダッシュ」は
| 16進コード | 名称 | 字形 |
| 0x8160 | 波ダッシュ (WAVE DASH) |
 |
このように定義されています。
[Unicode]の「WAVE DASH」を見てみると、
| 16進コード | 名称 | 字形 |
| U+301C | WAVE DASH |  |
と定義されています。
この2つの定義、比べてみると何かおかしいですよね?よく見ると(見なくても?)字の形が違います。
[Shift_JIS]の「波ダッシュ」は左から「上がって下がる」字体なのですが、[Unicode]の「WAVE DASH」は、左から「下がって上がる」字体が定義されているのです。
では、[Shift_JIS]とおなじ字体の文字は[Unicode]に無いのか、と探してみると…ありました。
| 16進コード | 名称 | 字形 |
| U+FF5E | FULLWIDTH TILDE | |
このような文字が定義されています。
これらの定義から、[Shift_JIS]の[0x8160]は[Unicode]の[U+301C]と同じ名称で、[Unicode]の[U+FF5E]と似た文字の形をしている、ということがわかります。
[Unicode]の「WAVE DASH」の字形である、左から「下がって上がる」字体は存在していませんでした。
では、なぜもともと字体として存在していない、本来の字形と異なるものが[Unicode]の「WAVE DASH」として定義されてしまったかというと…
間違えた理由を再現することができます。
で、それを[Unicode]の「WAVE DASH」として定義しちゃった、という…
この誤った定義が訂正されずにそのままになっているせいで、面倒なことが起きているわけで…
「FULLWIDTH TILDE(全角チルダー)」という名称の文字は、[Shift_JIS]には存在しません。
そもそも「TILDE」という記号は、上の方の位置にニョロっと出る記号です(通称はそのまんま“ニョロ”)。
もともとこの記号:チルダーは、アルファベットに対して発音などを区別する場合に付与する記号(diacritical mark)で、英文タイプライターの時代には、アルファベットをタイプして、[BS]キーで1文字分位置を戻してから、タイプしたアルファベットの上から重ねてチルダーを入力する、といった使い方をしていた記号ですから、そもそも日本語には存在しない記号なのです。
もともと半角の「TILDE」を全角にしたら、たまたま似た文字になっただけで、生い立ちも意味も「波ダッシュ」と「全角チルダー」は異なるものと覚えておけるとよいでしょう。
では、「波ダッシュ」における、[Shift_JIS]と[Unicode]の変換がどう定義されているのか見てみます。
まず、Unicodeコンソーシアムが定義している変換はどうなっているかというと、Unicodeコンソーシアムが公開している、「Shift-JIS to Unicode」の2011/10/14版テキスト( ftp://ftp.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/SHIFTJIS.TXT )には、
0x8160 0x301C # WAVE DASH
と定義されています。
そして、この変換テーブルには[U+FF5E](FULLWIDTH TILDE)は記載されていません。
この変換テーブルに従うと、次のような変換が行われます。
| Shift_JIS | >Unicode | |
| 0x8160 |
←→ | U+301C |
| 対応文字なし | ← | U+FF5E |
Unicodeコンソーシアムのマッピング定義は、文字の名称に従った変換です。というか、もともと[Unicode]の規格書にある「WAVE DASH」の項目には、
This character was encoded to match JIS C 6226-1978 1-33 “wave dash”.
と記述されています。この記述から[Shift_JIS]の「波ダッシュ」のために作られた文字、ということがわかります。ですから、これが正しいマッピング…なのですが、[Shift_JIS]と[Unicode]の「WAVE DASH」のところでも記載したとおり、字形が違う文字になってしまいます。
日本語の見た目としてはおかしいのですが、定義としては正しい変換、ということになります。
一方、Microsoftが定義している変換はどうなっているかというと、MSDNにある「Windows Codepage: 932 (Japanese Shift-JIS)」( http://msdn.microsoft.com/en-us/goglobal/gg638593 )には、
8160 = U+FF5E : FULLWIDTH TILDE
と定義されています。
そして、この変換テーブルには、[U+301C](WAVE DASH)は記載されていません。
この変換テーブルに従うと、次のような変換が行われます。
| Shift_JIS | Unicode | |
| 0x8160 |
U+FF5E |
|
| 対応文字なし | ← | U+301C |
Microsoftは、日本語の「波ダッシュ」と同じに見える、左から「上がって下がる」字体の「FULLWIDTH TILDE」を変換先に割り当てました。これにより、見た目は同じになったのですが、結果として本来の文字とは異なる16進コードに変換されることになりました。
日本語の見た目としては正しいのですが、定義としては誤った変換、ということになります。
Windowsのメモ帳などで「~」を入力し、Unicodeで保存すると「U+FF5E」で保存されることが確認できますし。また、Windowsに付属している「文字コード表」でも確認することができます。
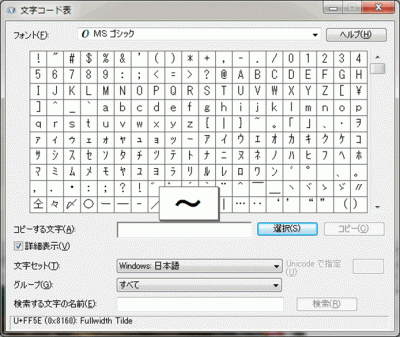
Windows 7の文字コード表で、文字セットに「Windows: 日本語」を選択し(=MS932)、「~」を選択した画面。
ステータスバーに「U+FF5E (0x8160)」とあるように、「~」(0x8160)は、Windows 7でもU+FF5Eにマッピングされていることがわかります。
そして、UnicodeコンソーシアムのマッピングとMicrosoftのマッピングは共に、[Unicode]にある2つの16進コード([U+301C]と[U+FF5E])のいずれか一方のみが[Shift_JIS]の「~」に変換され、変換できない側の16進コードの文字が来ると「変換できない文字」という扱いになります。
Unicodeコンソーシアムが規定した標準的なマッピングとMicrosoftのマッピングとでは、異なるUnicodeの16進コードにマッピングされるため、それらが組み合わさると、「~」の文字化けが発生するのです。
Oracleデータベースの動作も、これら2つの変換パターンが元になっています。
その前に、Oracleデータベースの文字コード変換について説明します。
Oracleデータベースは、データベースとクライアントで利用する文字コードを設定しています。[Shift_JIS]に対応した[NLS_LANG]には、「JA16SJIS」と「JA16SJISTILDE」の2種類があります。例えば、x64版の[Oracle Database Client 12c]をWindows 7 x64の日本語環境に導入すると、[NLS_LANG]には「JA16SJISTILDE」が設定されます。
クライアントから[Oracle Database Client]の[ODBC Driver]を使用してデータベースに接続する場合、クライアント側の文字コードは、クライアント側で設定した[NLS_LANG]に従います。
アプリケーションを使用している場合は、そのアプリケーションに従います。例えばそのアプリケーションがUnicodeアプリケーションであれば、[NLS_LANG]で指定した文字コードではなく[Unicode]で受け取ります(アプリケーションの作りにもよりますが)。
データベースとクライアントの[NLS_LANG]が同一である場合は、データベースとクライアントの間では文字コードの変換は行われずにデータがそのまま渡されるのですが、[NLS_LANG]が異なる場合や、アプリケーションが受け取る文字コードがデータベースと異なる場合は、Oracleデータベースが文字コードを変換して渡してくれます。
この文字コードの変換なのですが、変換元の文字コードから変換先の文字コードに直接変換されるのではなく、一旦[Unicode]に変換されてから変換先の文字コードに変換されます。
ここに、前に説明した[Unicode]が登場しました。イヤな予感がしますね。
Oracleデータベースにおける「~」の変換がどう定義されているのか見てみましょう。
| Shift_JIS | Unicode | |
|
0x8160
|
←→ |
U+301C
|
| ← |
U+FF5E
|
| Shift_JIS | Unicode | |
|
0x8160
|
← |
U+301C
|
| ←→ |
U+FF5E
|
「JA16SJIS」がUnicodeコンソーシアムの変換、「JA16SJISTILDE」がMicrosoftの変換に対応しているのですが、それらの変換テーブルと異なるところは、「相互変換されない側の文字も[Shift_JIS]の[0x8160]に返ってくる」ことです。
ということで、「~」が文字化けするのは、
データベースとクライアントの間のどこかに、文字コード変換を行うときに欠落する組み合わせが存在する場合
ということになります。
先にに提示した例、
Unicodeアプリケーションから、Oracleデータベースに格納されている「~」を参照したところ、「~」が別の文字に置き換わって表示された
では、
Oracleデータベースが、変換のためにデータを[Unicode]に変換したとき、「~」の16進コードをUnicodeアプリケーションがローカル文字コードに変換できない側の16進コードで渡されたことが原因として考えられます。その場合は、「サーバの[NLS_LANG]で調整」「アプリケーションで吸収」のいずれかの対応が必要です。
もともとOracleデータベースの[NLS_LANG]には、Unicodeコンソーシアムが規定した標準的なマッピングの「JA16SJIS」しかありませんでしたが、Oracle 9iから、Microsoftの変換マッピングでも変換できるように「JA16SJISTILDE」が用意されました。
どちらを使えば良いかは、システムに合わせて選択する必要があります。
[NLS_LANG]の「JA16SJIS」と「JA16SJISTILDE」では、「~」の扱いだけが異なるのですが、[Unicode]と[Shift_JIS]の変換で、UnicodeコンソーシアムとMicrosoftのマッピングが異なる文字は、ほかにもいくつか存在しています。
今回の「~」の文字化けと同様の問題は、他のデータベースにも存在しています。
Db2では「HINT&TIPS」として、クライアント側に持っている変換テーブルを差し替えることで、文字化けに対応できるようになった、とIBMのサイトに記載があります。マニュアルには記載されていませんが…
この記事はWindows環境で書いています。そして、過去の記事を確認してみたところ、記事中で「波ダッシュ」として書いた文字は、「全角チルダー」になっていました。これは誰が変換した結果なのでしょうね?

Rankingランキング
New arrival新着
Keywordキーワード