データドリブン経営の前提として考えるMVV:ミッション・ビジョン・バリューと戦略・戦術・戦法

SQLiteはオープンソースのライブラリー型データベースで、アプリケーションのメモリ中で非常に高速に動作します。
OracleやSQL Serverの何倍も高速です。
SQL構文もかなり標準対応が高度で、使用した限りクエリ結果も正確です。サーバー型ではないので、同時に一人だけしか使えませんが、複雑なデータ加工を、SQLエンジンを使用して操作するのには非常に適しています。

SQLite公式サイトはこちら
C言語等でアプリケーションを作成するなら、APIを用いてライブラリをリンクするのですが、作成したデータベースを汎用の検索エンジンで使用したり、アプリケーションを他のRDBMSでも動作するように作りたいなら、ODBC汎用にして開発するのが良いでしょう。
ただし、SQLite3はシフトJISに対応していないため、通常のODBCアプリケーションのルールでは文字化けしてしまいます。
オープンソースなので、シフトJIS対応したODBCドライバーも有志が提供しているようですが、今回ご紹介する方法で標準のまま対応可能です。
ODBCはデータ獲得のためにAPIで1カラムずつ取得する方法と、バインドバッファというメモリー領域に一度に取得する方法があります。
APIの場合、Unicodeアプリケーションならば、文字コードはワイド文字(Unicode)固定になり、SQLite3でも文字化けしません。
しかし、バインドバッファ経由では問題があります。
ODBCにはバインドバッファ上の文字コードを指定するAPIがありませんが、文字型をローカルコード(SQL_C_CHAR:日本語WindowsだとシフトJIS)かワイド文字(SQL_C_WCHAR:Unicode)に指定することはできます。
日本語WindowsではSQL_C_CHARで指定したときの文字コードはローカルコードつまりシフトJISがルールですが、SQLite3の場合はUTF-8になってしまいます。おそらく物理格納されているデータをそのまま返しているのでしょう。
文字コードをローカルコードでなくUTF8で扱えるツールはまず無いので、正しく日本語が扱えないわけです。
SQLite3で正しく日本語を扱うには以下のようにします。
注意するのは、ODBC設定で「NO WCHAR」チェックをオンにしないことです。これはデフォルトがオフなので、自分で変更しない限り問題にはなりません。
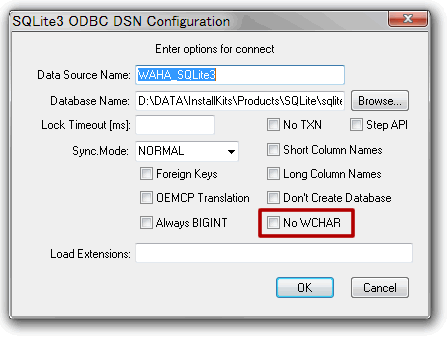
データ加工シーンでは文字化けの危険を避けるため、入力データと同じ文字コードでデータベースを構築し、ODBC等のインターフェースでコード変換をさせないように配慮するのですが、Windowsでは基本的にUnicode-シフトJIS間の文字コードは相互変換が保証されているので、Windowsで使用する限りは文字化けの危険は無いと思います。
しかし、データの提供元がメインフレームやUNIXなどWindowsでない場合には、アプリケーションで投入するデータがWindowsで許されるコード範囲内にあるかどうかチェックする等の対応が必要でしょう
SQLデータベースの話(その2)ODBCドライバと各社RDBクライアント文字コードの関係
20年以上の実績に裏打ちされた信頼のデータ連携ツール「Waha! Transformer」で、自社に眠るデータを有効活用。まずは無料のハンズオンセミナーや体験版で効果を実感していただけます。

Rankingランキング
New arrival新着
Keywordキーワード