ビジネスを飛躍させるデータドリブンの力
先日こんなニュースがありました。
将来、球審がロボットに? ストライク機械判定、米独立Lで既に試験導入
おー、ついに。
よく国際試合なんかで「メジャーの審判は外角に厳しい」とか言われてたりします。
先日の「WBSCプレミア12」(準決勝は本当に残念でした・・・)では、日本の選手が外角の球を見送って見逃し三振を取られた場面も多く見られました。
個人的には「おいおい、マジかよ」みたいな表情で、ベンチに帰っていく坂本選手(巨人)が印象的でした。
日本のプロ野球においても、審判一人ひとり、クセがあるとは言われています。
なかなかストライクを取らない、とか、中には「・・・あれ、試合中にストライクゾーン変わってないか?」と思われるようなケースもあったり。※以下、個人の感想です。
実際に野球中継を見ていて、贔屓のチームのピッチャーがフォアボールを出した際、「おい!(ストライク)入ってんだろ!」
↓
(ビデオによるスロー再生)
↓
「やっぱ入ってるじゃねぇか!」
みたいな場面も割りと良くあります。
これが球場での観戦だと、ビールの追加に大きく寄与する訳です。
そういう点からすると、AI・人工知能による審判の判断支援はすごく朗報。
でも個人的には、敷田球審が見逃し三振を取る時のジェスチャーがすごく好きなので、それが見れなくなるのは残念。
(暇な方は是非youtubeで「敷田 卍」とお調べくださいませ)
ストライク・ボールの判定ならば、空間上に座標を固定して、その中を通ればストライク、みたいな感じで割りとイケそうな感じはありますが、将来的には、ベース上におけるクロスプレーのジャッジとかも機械化されるんでしょうか。
ホーム上の際どいプレーでアウトorセーフの判定になった時、不利な判定を受けた監督がダッグアウトを飛び出る瞬間のスタンドの盛り上がりは、ある種、球場観戦の醍醐味な気もしますが。
恐らく、ここで寄与する技術としては、深層学習が挙げられると思います。
画像認識とかで世間を騒がせている例のアレ。そう、ディープラーニング。
もう今更の今更ですが、「ディープラーニングによる画像認識」みたいなキーワードでググって見ると大量の記事が出てきます。
ただ、大半が「オープンソースのライブラリを使って実装してみよう」みたいな切り口で、「まずは環境設定して・・・(専門用語ドバー」、「次にデータセットが・・・(Excelドバー」、「で、プログラムを記述してっと・・・(コードドバー」 。
なるほど、わからん! と、なりがちじゃないかと。
「いや、そんな難しいコトはしたくないしよく分からない」という人も多くいらっしゃるかと思います。
・・・いらっしゃいますよね?
そこで今回の記事では
「そもそもディープラーニングって何してんのよ、これ?」
ってとこに絞って書いてみたいと思います。
ディープラーニングのとにかく浅いところから。
みたいなことは、他にもいくらでも記事があると思うので、
当記事では以下、一切書きませんのであしからず。
まずはこちらの写真をご覧ください。
 にゃー
にゃー
ちょっとファンキーな表情を見せていますが、どう見てもネコです。
人が見れば、そういう判断になりますが、機械≒コンピューターの場合、どう処理をするのか見てみましょう。
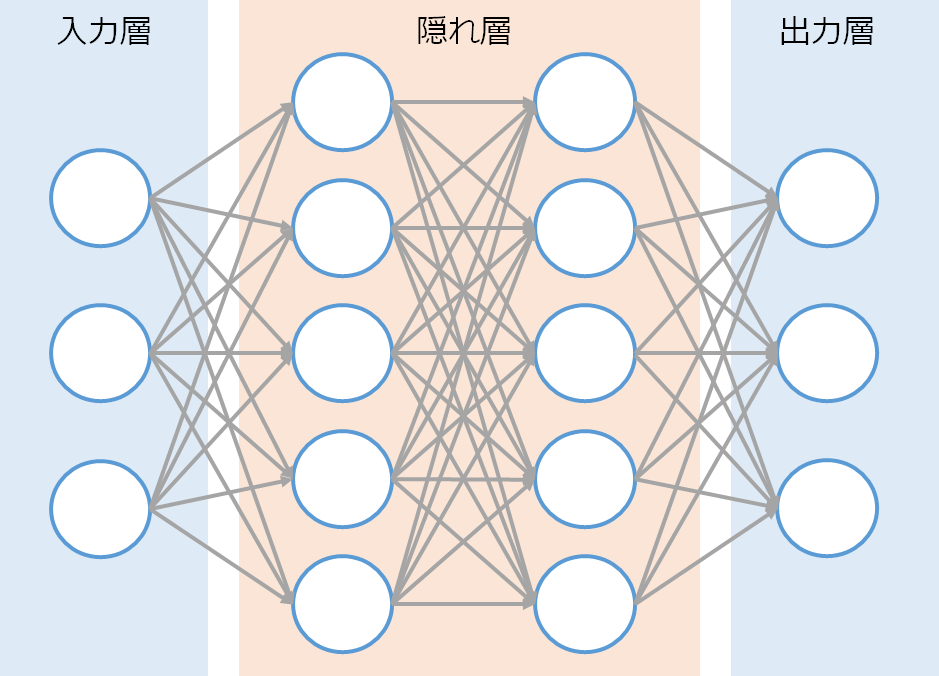
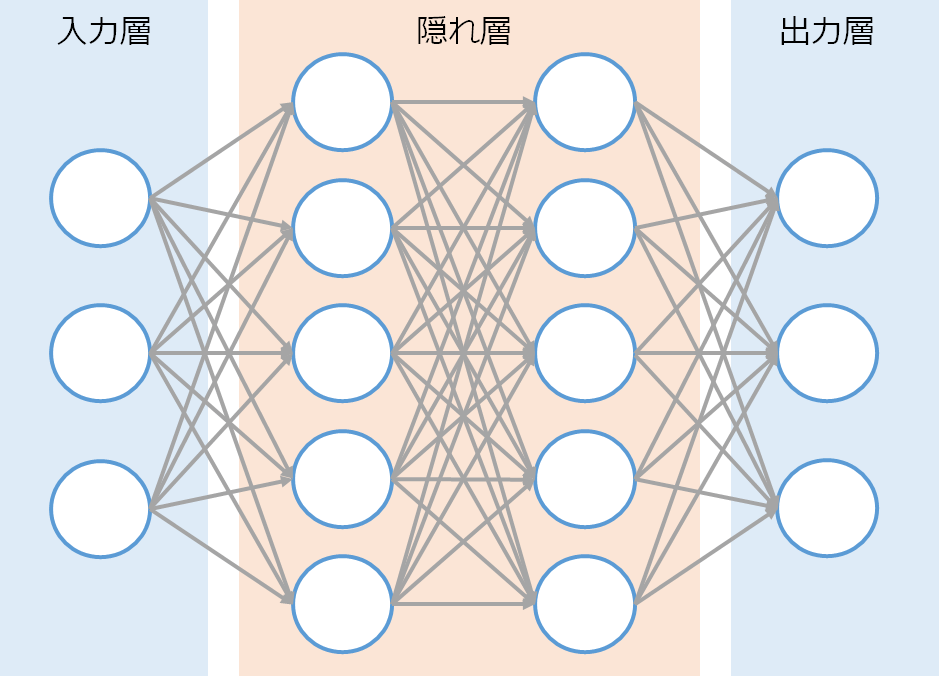
「ディープラーニング」で調べてみると、↓のような概念図が出てきます。
 (ディープラーニング概念図)
(ディープラーニング概念図)
そもそも機械学習は、人の脳の働きをコンピューターによって機械的に再現しようとしたものであり、この図はその働きを示したものですが、本記事ではもっとポップに記載してみます。
まずは「入力層」から。
彼らは何をするかというと、画像を細かく刻んで、各々で与えられた箇所を見ます。
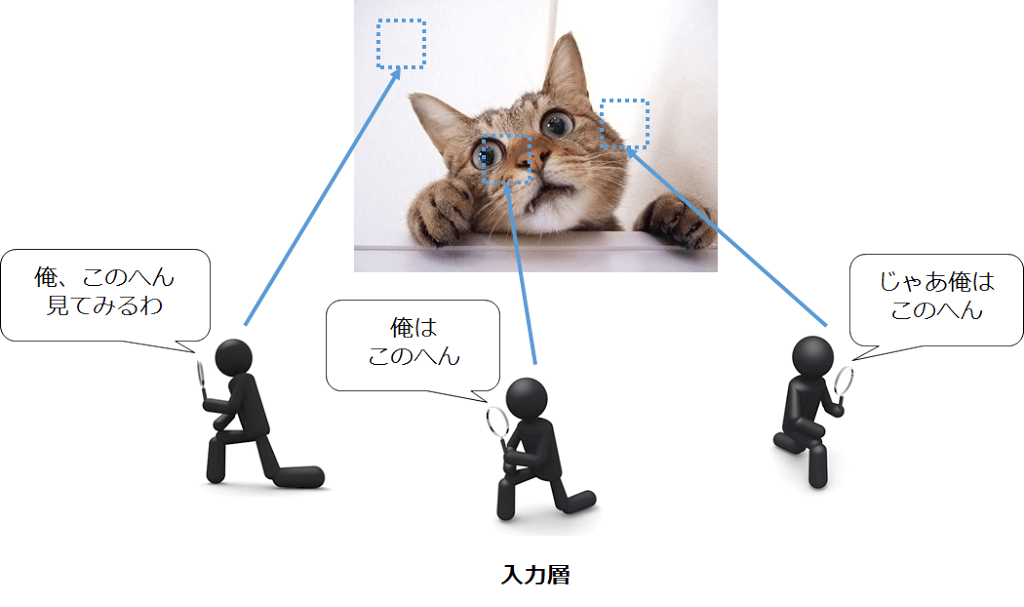
その後、「入力層」から「隠れ層」に情報を伝達します。
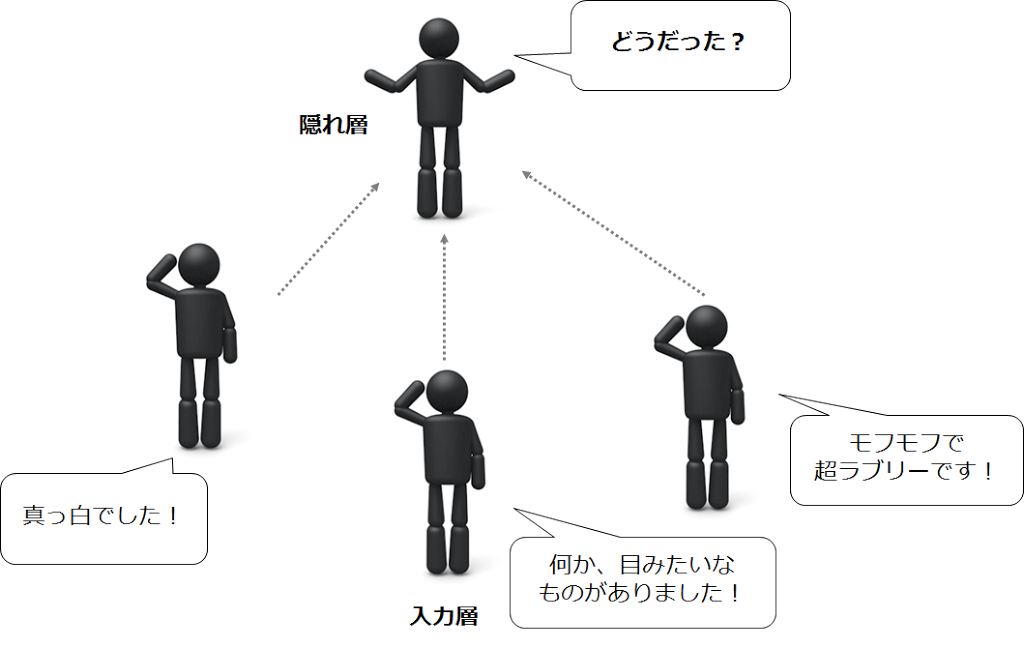
隠れ層はモデルによって何層~何十層もあり、(この層の深さが"ディープ"ラーニングの由来)
浅いところにいる隠れ層から、深いところにいる隠れ層に情報を伝達します。

隠れ層では、深いところに進むにつれ、情報が集約されていき、最終的に出力層が判断を下します。
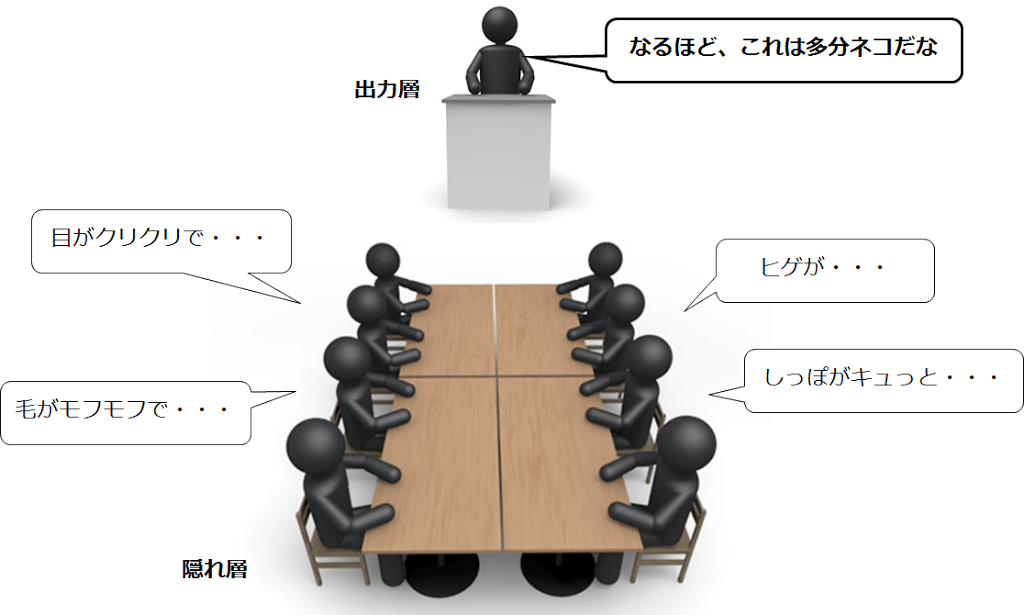
こうして、この画像がネコであると判断される訳です。
ところで最初の概念図(↓)のサンプルでは出力層が複数ありました。
これはどういうことかと言うと、他の出力層ではこんな感じになってます。
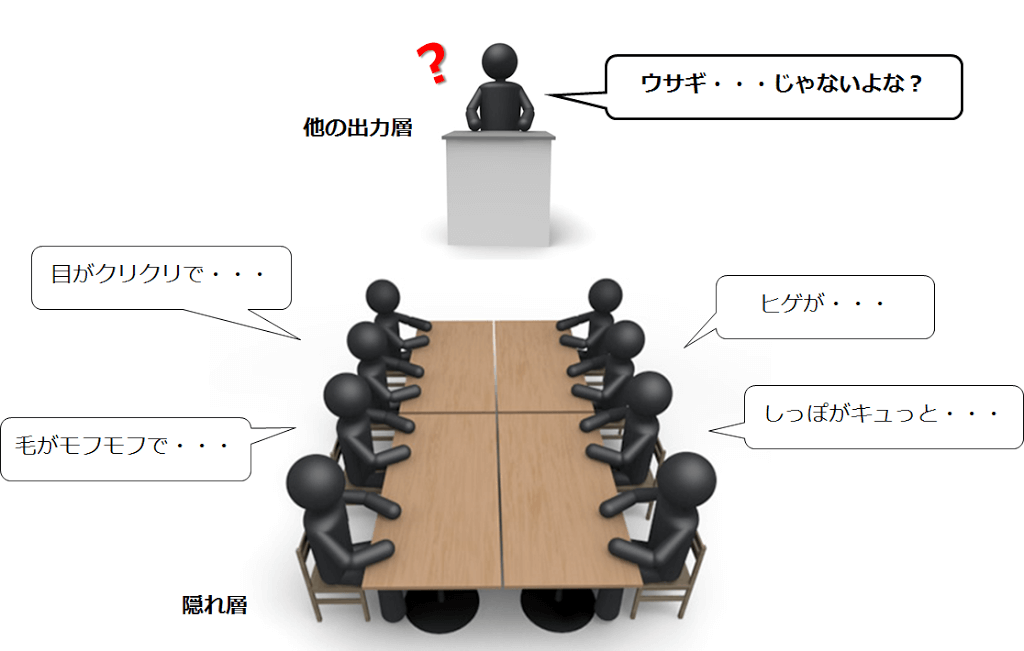
極端な例になってしまいましたが、出力層をどう設定するかによって、例えば同じネコであっても、品種別に認識することもできるようになっていきます。
(Googleが発表したネコの写真認識のパターンなど)ところで、当然彼らも最初から「ネコ」という存在を知っている訳ではないので、最初に「教師データ」を与えてあげる必要があります。
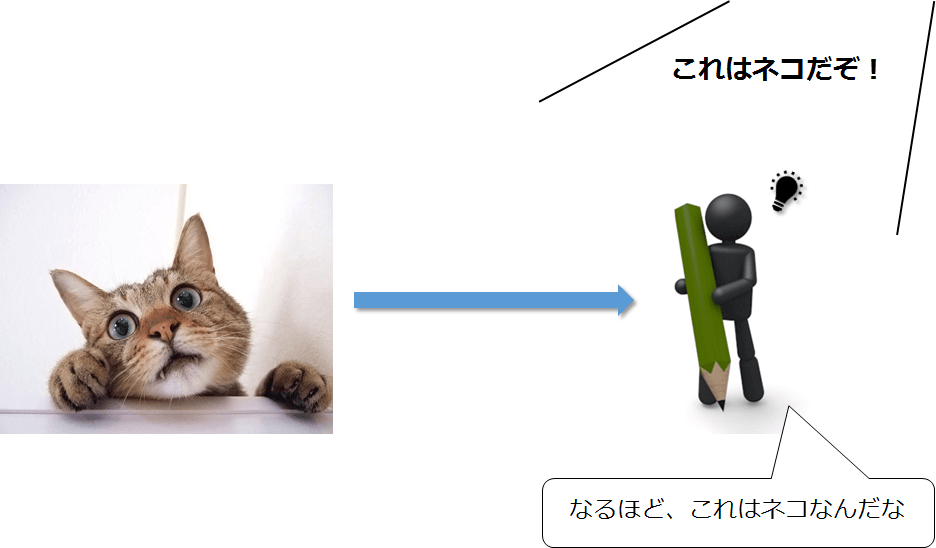
この教師データを何パターンも与えてあげることで、彼らも学習していきます。
これが「教師あり学習」です。
今回は、画像認識という切り口でしたが、入力データは画像に限らず、普通のデータ(数値・文字)などでも同様の動きをします。
ところで、このディープラーニングを用いる際に注意すべき点としては、「各層の数が多ければ多い程良い」という訳ではありません。
例えば下記のような図。
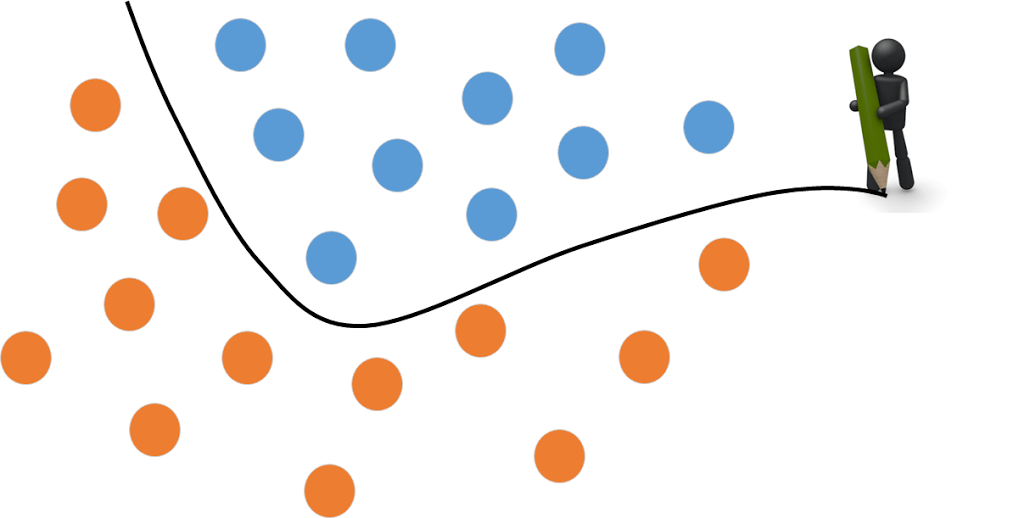
イメージとして青い●がネコ、オレンジの●がそれ以外の動物としましょう。

ディープラーニングはこれらの●を区別する上で、境界線を引くイメージです。
隠れ層の数が少ないと、↓のようなざっくりとした線を引きます。
逆に隠れ層の数を増やすと、↓のように厳密な境界線を引きます。
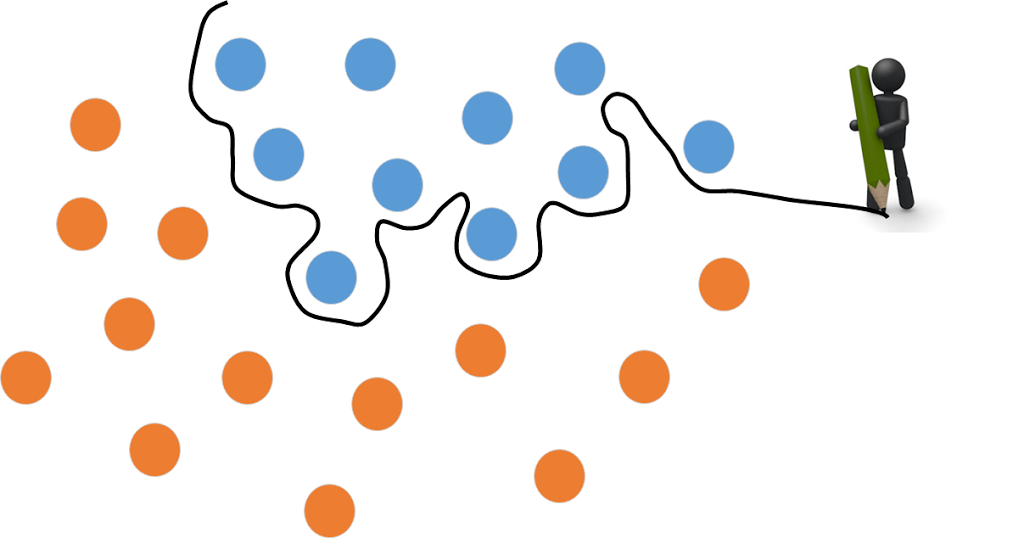
このように境界線が厳密になってくると、新しいデータを分類させた際に・・・
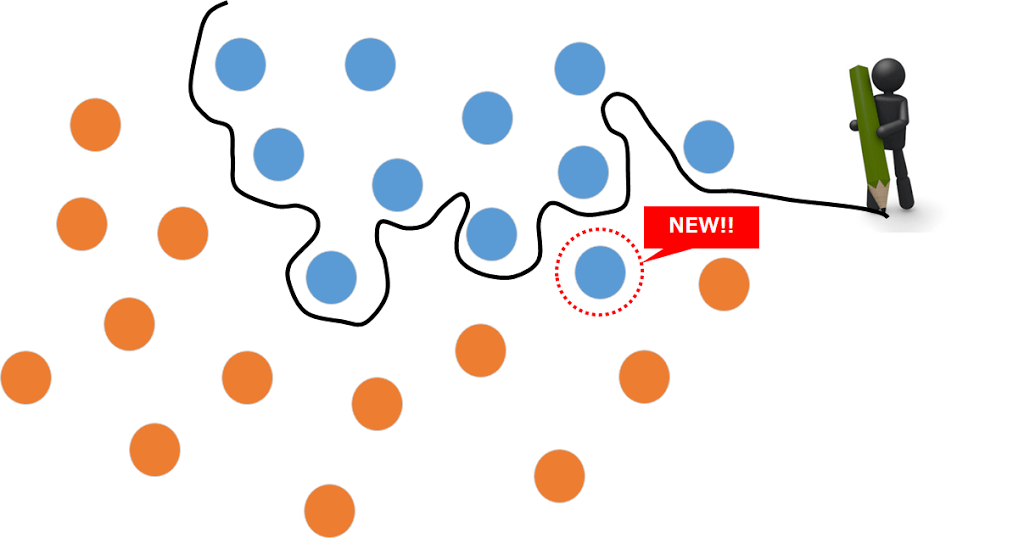
本来ならば、ネコであるにもかかわらず、境界線が厳密すぎるせいで、ネコと判断されなくなってしまうこと起きえます。
もちろん境界線が緩すぎる場合も、認識の精度が下がることになります。
この辺の塩梅(チューニング)がディープラーニングを活用する上で、一番苦心する部分になるのでしょう。
と、非常にざっくりとポップな感じで、ディープラーニングの浅いところについて書いてみました。
もっと実践的な内容については、当ブログの過去アーカイブに色々なツールを使った例を記載した記事がありますので、そちらも併せてご参照頂けますと幸いです。
・・・冒頭の野球、全然関係なくなっちゃいましたね。

Rankingランキング
New arrival新着
Keywordキーワード