データドリブン経営の前提として考えるMVV:ミッション・ビジョン・バリューと戦略・戦術・戦法

メインフレームからの交換データで、数値フィールドの1桁目がアルファベットになっているので、数値として読み込めないことがあります。<br/ > これは、COBOL等で生成したファイルをそのまま転送ツールの文字コード変換にかけて生成したのが原因と考えられます。
COBOLでよく使用される数値型にはパックとゾーン(アンパック)があります。<br/ > パックは、8ビットの上位下位をそれぞれ数値の一桁とし、1桁目を符号とします。
小数点位置は固定で、扱うアプリがフォーマットで定義します。つまり、データ中には小数点位置は記載されません。

アンパック(ゾーン)は、数値のキャラクタをそのまま書きますが、数値が負の場合のみ、1桁目にマスクがかかります。小数点の扱いはパックと同様です。
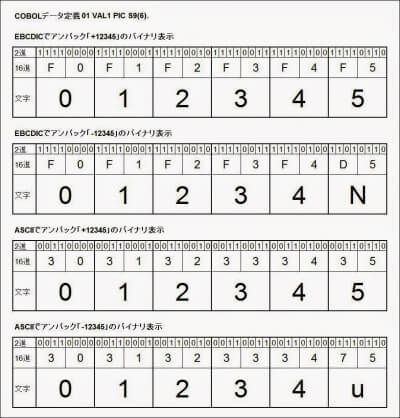
メインフレームでは数値文字列(「-1.123」のように見たままの形式)は可変長表現であることからあまり使用されないため、COBOLでデータ生成をする場合にはたいていパックかゾーンになります。パックはバイナリ表現のためデータのレコードレイアウトを意識しないとコード変換ができないため、ゾーンを使用する事が多いという事情があります。
問題は、サンプルデータが正の数値ばかりである場合、単純なEBCDIC/ASCIIのコード変換で大丈夫だろうと判断されてしまったことでしょう。
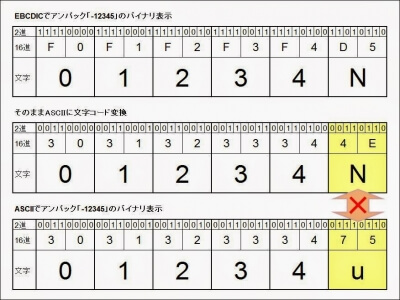
IBM COBOLのEBCDICのゾーンの場合、符号桁の上位4ビットは正の数の場合が0xF、負の数の場合が0xDなので、単純にコード変換した場合、相当する文字コードに変換されてしまいます。
負の符号桁は、ちょうどアルファベットの「}」から「R」に相当するため、変換後のASCIIデータの1桁目がアルファベットになるわけです。
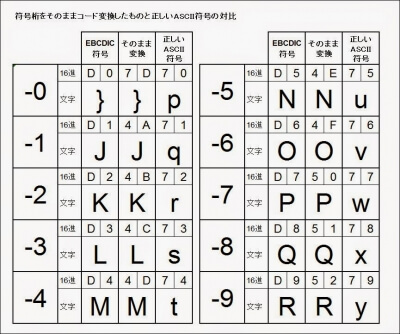
幸い、マスク後のデータは文字コードとして有効ですから、プログラムで判断する場合は、数値の1桁目がASCIIの数値コードに該当しない場合は負の数値として扱うことで対処できます。
一方、UNIXやWindows系のCOBOLでそのままデータを使用する場合は変換が必要です。
符号ビットは6ビット目が1になるという説もありますが、実はコンパイラメーカーごとに定義がバラバラで、単純変換した文字コードとも異なるためです。
データ提供元の人々は自分の言葉と常識で語るので、データ変換の仕様策定を行う場合には、相手先プラットフォームについての知識が必要になってくるわけです。
Waha! Transformer の対応データソースと対応文字コード体系
20年以上の実績に裏打ちされた信頼のデータ連携ツール「Waha! Transformer」で、自社に眠るデータを有効活用。まずは無料のハンズオンセミナーや体験版で効果を実感していただけます。

Rankingランキング
New arrival新着
Keywordキーワード